March 30, 2026
Building your own search intent with Bionoculars: A nuclear medicine use case
The scenario
A nuclear medicine researcher wants to find articles that evaluate the reliability of calcium scores estimated from nuclear medicine imaging (such as SPECT/CT) without running a full dedicated calcium score CT. Their starting query: "calcium score in nuclear medicine".
The challenge: understanding the user's intent is one of the hardest problems in information retrieval. In research, this is even harder because the user's intent is often not fully formed when they begin exploring a new topic (Peltonen et al., 2017).
Methodology
This test started with an interview with our nuclear medicine researcher. The interviewer explained how Bionoculars works, and the researcher guided the search on their own.
We did not know beforehand where the session would lead. It turned out to be a clear example of how Bionoculars helps users express and develop their search intent.
Comparisons with other tools were written afterwards with the interviewee's help, to avoid biasing the Bionoculars test by unconsciously looking for articles found by other tools.
Disclaimer: We are not evaluating the ranking algorithms of the tools discussed here. Our goal is to show how Bionoculars components, in particular keyword groups, combined with the principles of transparent and controllable AI, enable a different bibliographic research process, one that makes it easier for users to express their intent and build a comprehensive list of relevant literature.
What happens with conventional search
PubMed:
Of the top 10 results, only 5 mention both calcium score and nuclear medicine:
Best practice for the nuclear medicine technologist in CT-based attenuation correction and calcium score for nuclear cardiology. Campa, L., Santos, A. et al. (2020) A useful starting point.
Coronary Artery Calcium Scoring Using CT Attenuation Correction Images Obtained During Myocardial Perfusion Scintigraphy. Nishiyama, Y. et al. (2021) Treats calcium score in a separate acquisition.
Coronary calcium scoring of CT attenuation correction scans: Automatic, manual, or visual?. Damen, Z., Sjoerd, A. J. (2022) A good reference.
Google Scholar:
A few more relevant hits appear in the top 10, for example:
Best practice for the nuclear medicine technologist in CT-based attenuation correction and calcium score for nuclear cardiology. Campa, L., Santos, A. et al. (2020) A good start, as noted above.
Artificial intelligence for automatic calcium scoring in nuclear cardiology using SPECT/CT. Slomka, P. J. et al. (2022) The first article addressing the use of AI in calcium score assessment using SPECT/CT.
Calcium scoring in nuclear cardiology: current challenges and future perspectives. Gimelli, A. et al. (2024) The first article that directly addresses the user's intent, but is not one of the most cited in the matter.
To be clear, with careful query crafting these tools can go further. The problem here is about intent: the researcher has a specific need that a broad initial query cannot communicate, and these tools offer no help in refining it. The main option is to rephrase the query and try again, hoping for a better match. This trial-and-error process adds friction that compounds quickly in large bibliographic projects, and it is not always obvious how to reword a query.
What happens with chatbots
Claude Opus 4.6: Claude covers the topic correctly but frames it primarily through the standard CT-based approach, giving nuclear medicine aspects secondary treatment. The main drawback: the mentions of SPECT/CT and PET/CT lack the supporting articles that would let a researcher verify the claims and ensure the answer is aligned with what the researcher is looking for.

Claude Opus 4.6 initial response: accurate but CT-centric, nuclear medicine aspects are secondary.
When asked to provide citations supporting its initial answer, we notice that the LLM revisits and expands its answer by adding new elements, which raises concerns about reliability: the first response was incomplete, and there is no way to know if the second one is complete and what it missed.

Claude's follow-up response with citations: new elements appear that were absent from the first answer.
Citations are not provided automatically. Initial answers can be incomplete, and we cannot see what the model has considered or overlooked.
A single citation per statement is not enough to support a research decision. More iteration is needed, with no guarantee the AI will produce a thorough overview.
As Messeri & Crockett argue, AI tools can create illusions of understanding, a risk that is particularly acute when users cannot see the evidence behind a confident-sounding answer (Messeri & Crockett, 2024).
Consensus: When it comes to citations, Consensus does significantly better: citations are provided by default, with multiple references per statement.
Consensus overview with citations: better than Claude, but shortcomings remain on closer inspection.
However, digging into the results reveals shortcomings:
Machine learning-based calcium scoring using attenuation correction CT in hybrid SPECT/CT and PET/CT. Tzolos, E. et al. (2019) (citation 16)
Cited to support a claim about SPECT/PET systems, but the article only mentions SPECT/CT and PET/CT in the introduction and focuses on cardiac and chest CT. The user needs to follow the article's references to find:
An Assessment of Incremental Value of Coronary Artery Calcium Scoring. Greenland, P. et al. (2010)
The second main citation (citation 13) is not sufficient on its own, as we discussed earlier:
Best practice for the nuclear medicine technologist in CT-based attenuation correction and calcium score for nuclear cardiology. Campa, L., Santos, A. et al. (2020)
Several cited articles focus on methods not directly related to nuclear medicine:
Photon-counting CT for coronary artery calcium scoring. van der Werf, N. R. et al. (2023) (citation 3)
Deep Learning-Based Coronary Artery Calcium Scoring in Cardiac CT Scans. Hecht, H. et al. (2021) (citation 4)
Again, we could likely obtain a good overview by iterating. But each iteration adds friction, and the outcome depends on the user's experience with LLMs and their ability to push beyond the tool's default behavior. Consensus has a query suggestion component after the overview that is meant to help in these cases, but it still misses the core user intent.
Consensus query suggestions: meant to help refine the search, but the nuclear medicine angle is still missing.
The same search in Bionoculars
In Bionoculars, like in PubMed and Google Scholar, the first two results focus on calcium score broadly. What is different is that the user can see the keyword groups: the indexing data and logic behind each result.
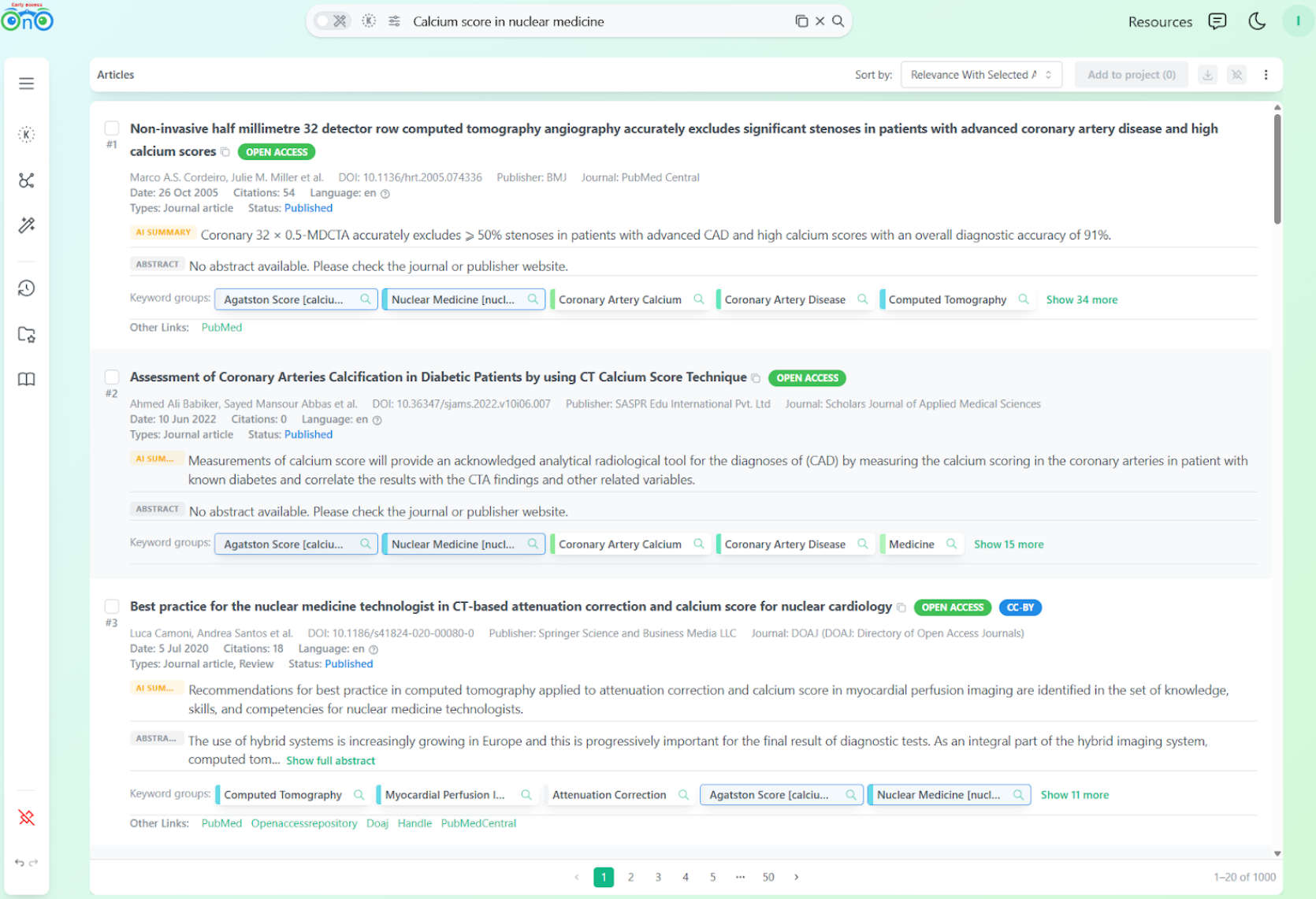
Initial Bionoculars results: the keyword groups panel makes the indexing logic visible.
This makes it easy to see where the mismatch between query and intent happened. We prefer showing these imperfections openly: it helps us improve the tool and gives users better control over the product they pay for.
The principle behind Bionoculars' keyword groups is similar to previous research showing that interactive keyword-based intent modeling improves search task performance (Peltonen et al., 2017).
At position 3, the researcher finds the same article as PubMed and Google Scholar. But this time, among its keyword groups, they notice:
Attenuation Correction: This points toward what they are actually looking for.
Myocardial Perfusion Imaging: Exactly what they would have added to the query if they had rephrased it manually.
The path forward is intuitive. The researcher directly thought about adding the missing keywords and did not even feel the need to continue checking the top 10. Instead of rewriting the query, they selected the keyword groups for "Attenuation Correction" and "Myocardial Perfusion Imaging" and added similar ones. This single step reshapes the results.
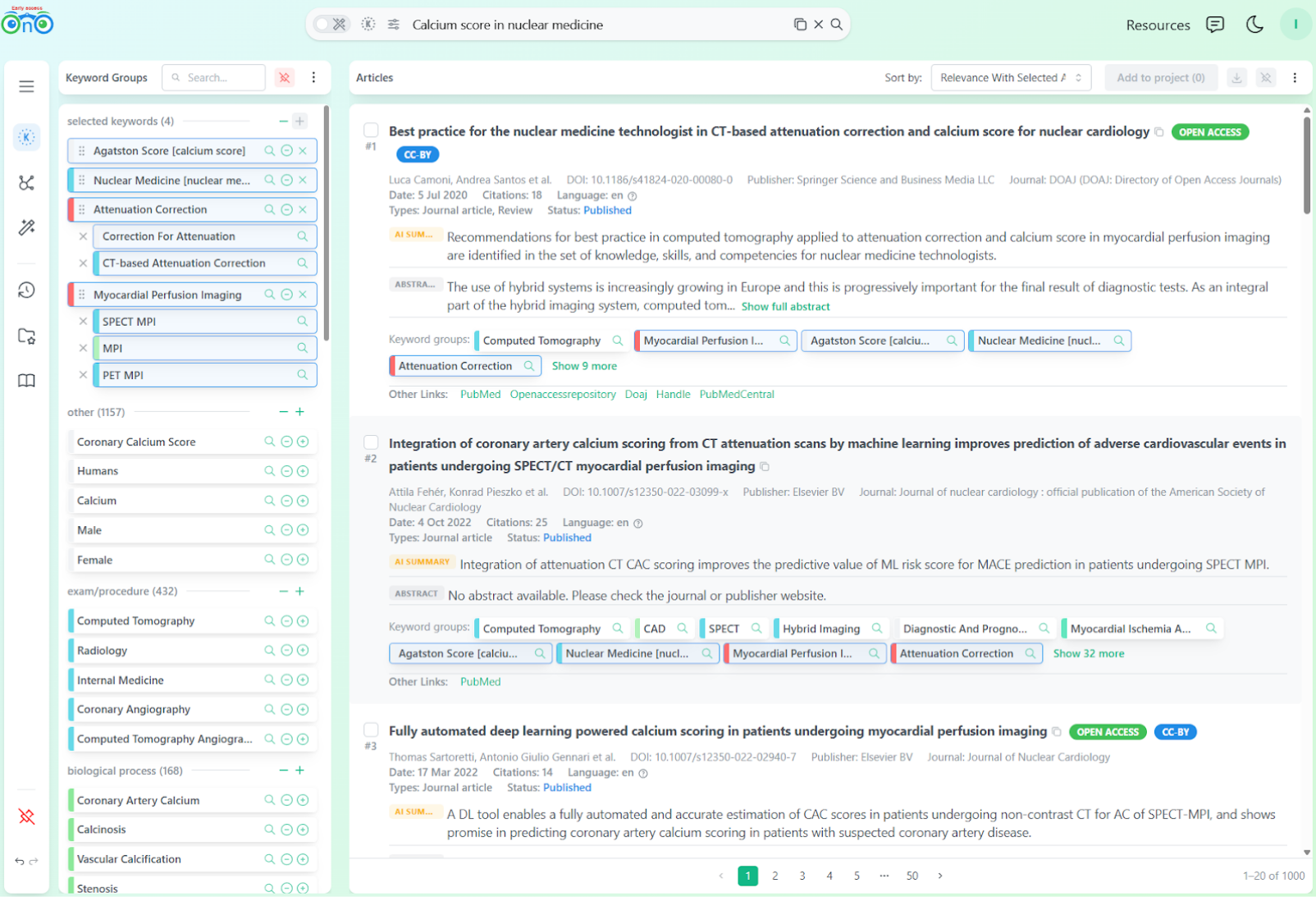
After selecting "Attenuation Correction" and "Myocardial Perfusion Imaging": the results are immediately more focused.
Note: for the comparison to be fair, we should have iterated for the other tools as well. But what we want to highlight here is that the iteration was automatic, intuitive and did not add any friction. The researcher did not have to guess or rewrite their query: they just reordered the first results using the data shown to them.
The key idea: Bionoculars makes its reasoning visible so you can correct it. It gives you the building blocks to express and refine what you mean, at your own pace, using your own expertise.
Learn how keyword groups work in the documentation or follow the tutorial.
Building the search iteratively
By selecting and combining keyword groups, the researcher starts finding exactly what they were looking for:
Best practice for the nuclear medicine technologist in CT-based attenuation correction and calcium score for nuclear cardiology. Campa, L., Santos, A. et al. (2020)
Coronary calcium scoring of CT attenuation correction scans: Automatic, manual, or visual?. Damen, Z., Sjoerd, A. J. (2022)
An Assessment of Incremental Value of Coronary Artery Calcium Scoring Above Traditional Risk Factor Assessment. Greenland, P. et al. (2010)
Visual assessment of coronary artery calcium score from CT attenuation correction images. Goha, A. et al. (2013)
Coronary calcium scoring of CT attenuation correction images in nuclear cardiology. Chang, S. M. et al. (2017)
Among the new top 10, seven matched the researcher's intent and directly talked about using SPECT/CT attenuation correction CT for calcium score. These articles were there in the results; they were also returned by PubMed and Google in the top 100. What Bionoculars did differently is that it gave the user enough control to surface them quickly, without scrolling through pages of less relevant results.
The researcher can then add these articles to a project for later reading.
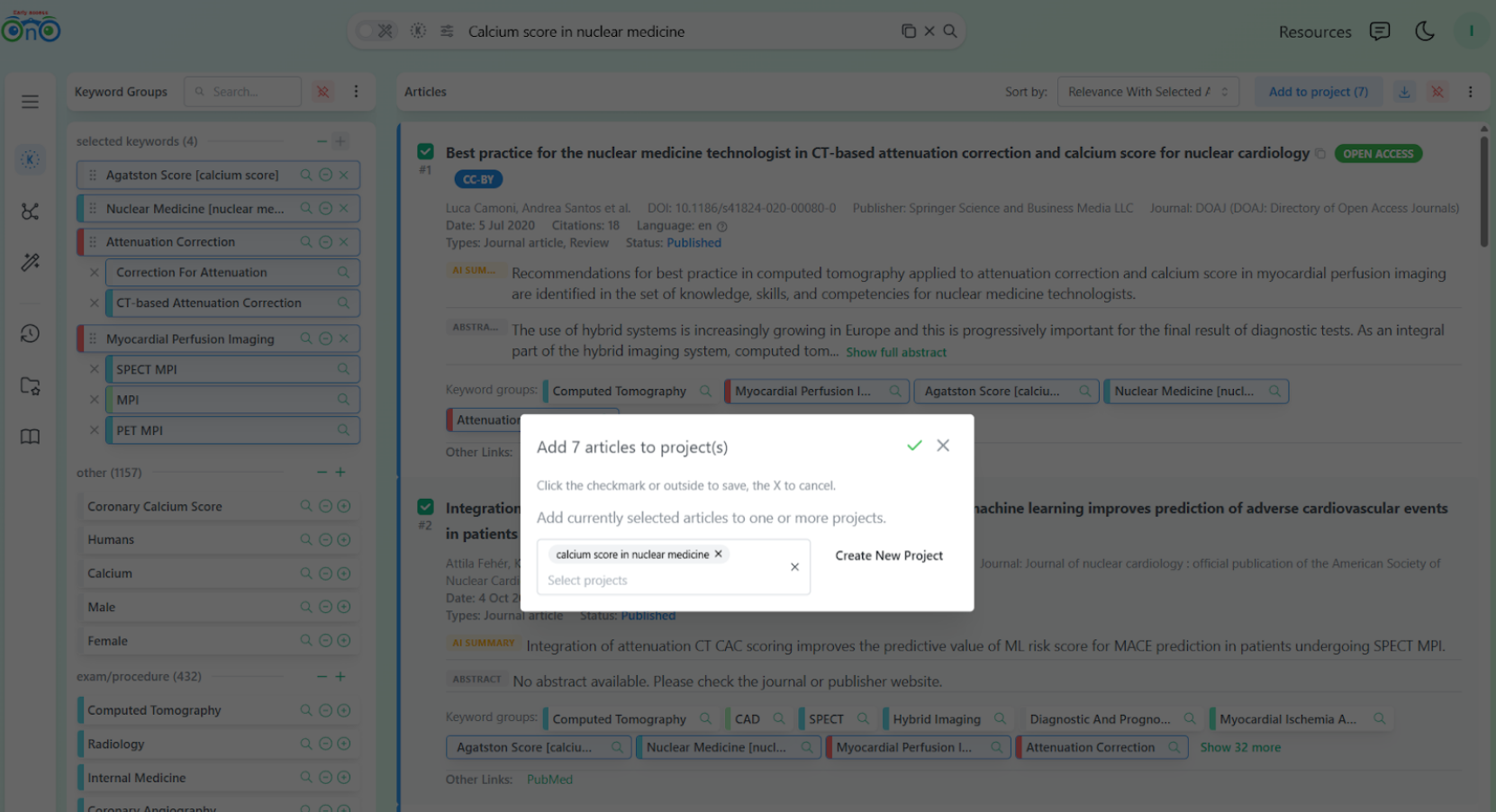
Adding the relevant articles to a project in one step.
Each step is a small, deliberate decision. The researcher is not hoping the algorithm gets it right, and does not need to construct complex boolean expressions from the start.
Where to go from here
At this point, the researcher has several options:
Explore the knowledge graph, which can surface additional relevant articles through concept relationships (documentation).
Use AI to summarize the articles collected so far, using their abstracts as input (documentation).
Use AI to find new articles via the Select and Generate action.
Run a new search, building on the keyword groups already identified.
We recommend the last option. With a more precise keyword set in hand, a new search will surface a fresh set of relevant articles. This is why we added the "Add to Search" button for each keyword group: it builds a refined search using Bionoculars' index keywords directly.
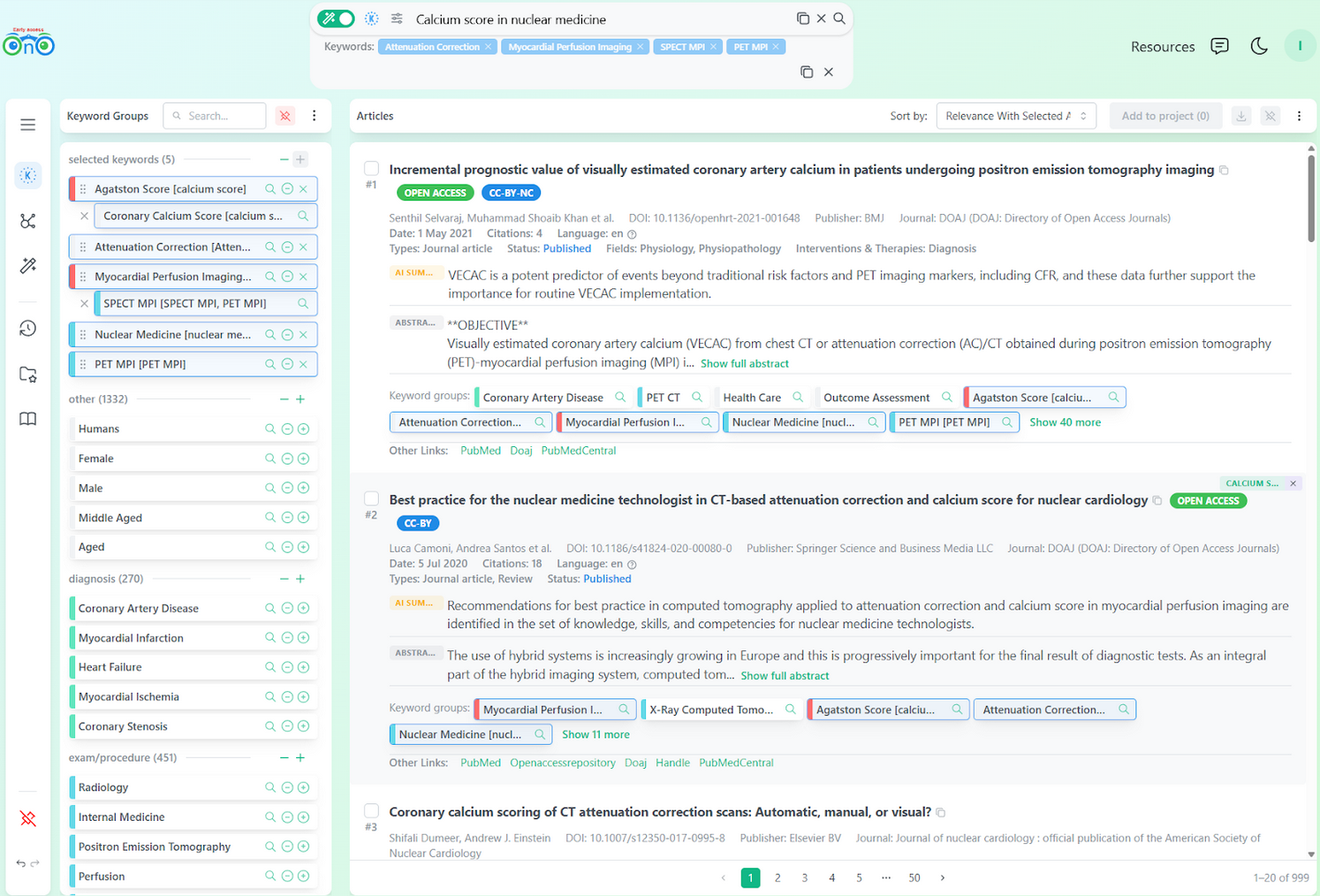
A new search built from the keyword groups identified in the session.
After this, the researcher quickly reorders and groups keywords to further express their intent. Five new articles appear:
Coronary calcium scoring of CT attenuation correction images in SPECT myocardial perfusion imaging. Chang, S. M. et al. (2017)
Reproducibility of quantitative coronary calcium scoring from PET/CT attenuation maps: comparison to ECG-gated CT. Paulus, G. M. et al. (2020)
Working with a project
Once the articles are saved to a project, the researcher can run AI queries restricted to that set. This helps prioritize which papers to read first and filter down to the most relevant subset.
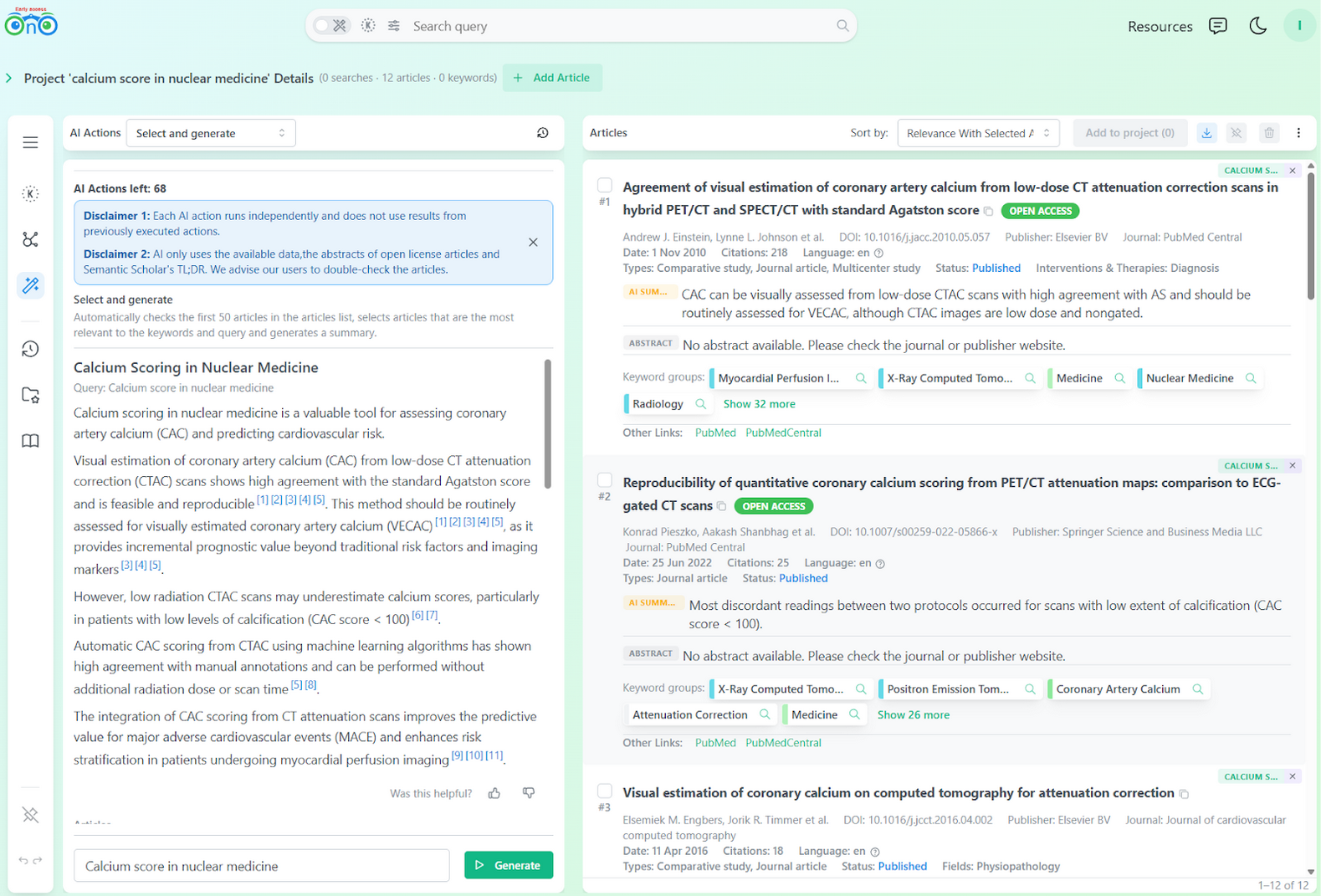
AI action (Select and Generate) restricted to the project's collected articles.
Using LLMs at the end of the process instead of the start mitigates the drawbacks we described earlier. The AI action is used to assist in building a focused overview for better decision making and is not meant to replace the expertise of the researcher.
Summary
The tools we compared each have specific shortcomings for this kind of exploratory research, where intent is not fully expressed or developed from the start:
Search engines (PubMed, Google Scholar):
Do not help the user express or develop their intent.
Require the user to craft the right query to match the engine's index.
Results were dominated by one facet of the query (standard calcium scoring), while the nuclear medicine angle was underrepresented, and it is not always clear how to control this balance.
LLM chatbots (Claude Opus 4.6 and Consensus):
Lack of reliability: citations are not always present, and initial answers can be incomplete, and in some cases are not used correctly when present.
Lack of transparency: there is no way to see which articles were considered or overlooked, or why certain claims were made.
Lack of control: the user cannot steer the output without reprompting and hoping the model interprets the correction correctly.
Bionoculars: Makes its reasoning visible so you can correct it. It gives you the building blocks to express and refine what you mean, at your own pace, using your own expertise. Each step is a small, deliberate decision. The researcher is not hoping the algorithm gets it right, and does not need to construct complex boolean expressions from the start.
References
[1] Peltonen, J., Oulasvirta, A., & Kaski, S. (2017). Interactive Intent Modeling from Multiple Feedback Signals. ACM Transactions on Interactive Intelligent Systems, 7(2), 1-36. https://doi.org/10.1145/3231593
[2] Messeri, L. & Crockett, M. J. (2024). Artificial intelligence and illusions of understanding in scientific research. Nature, 627(8002), 49-58. https://doi.org/10.1038/s41586-024-07146-0